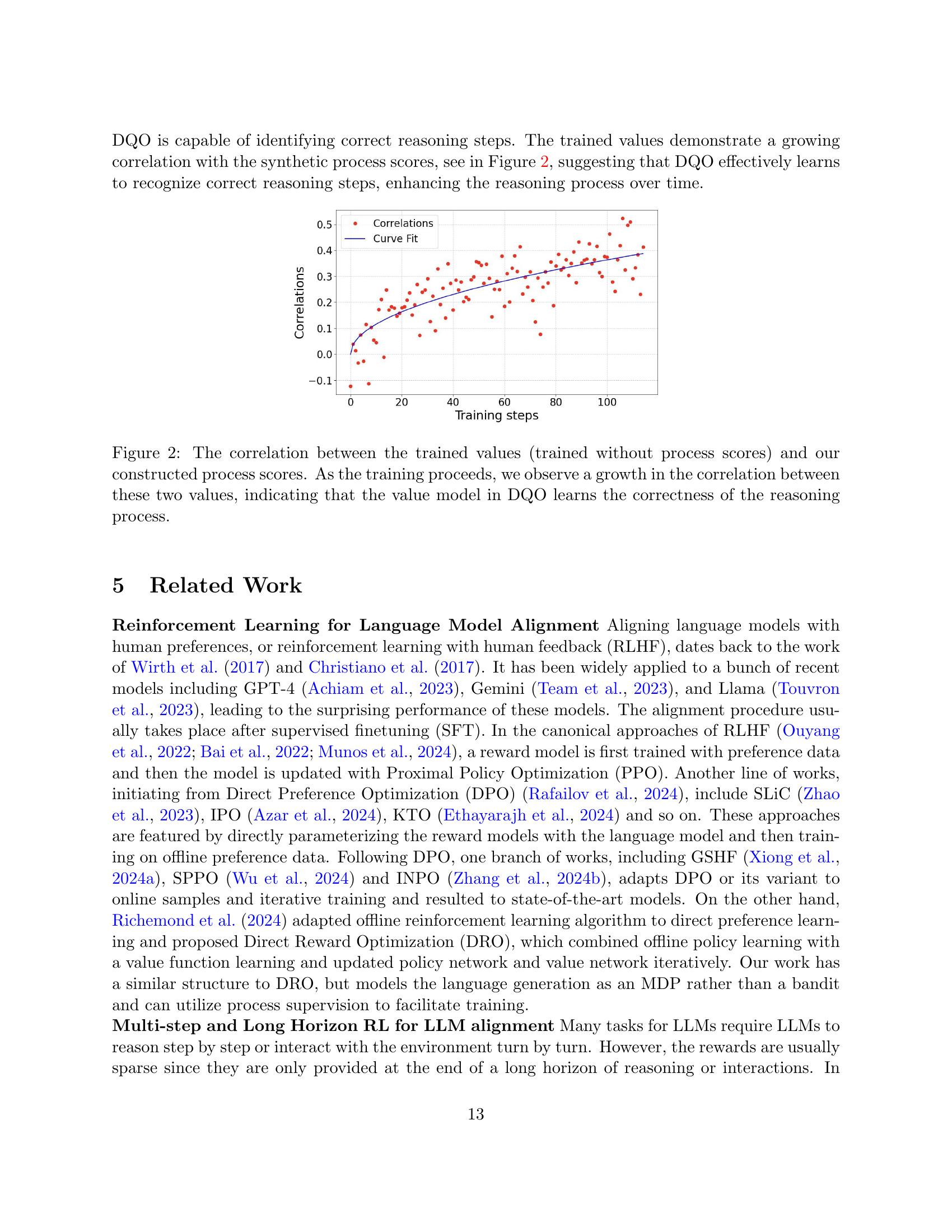
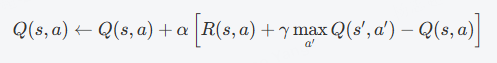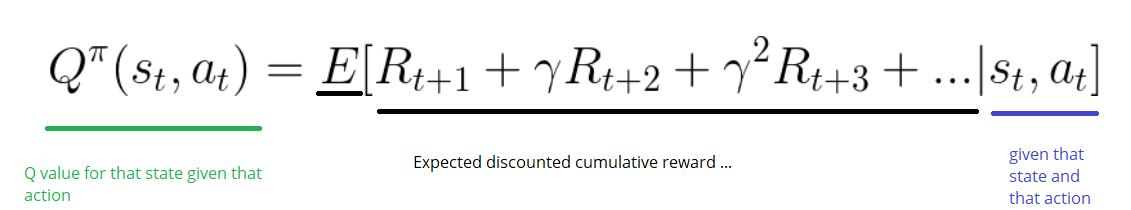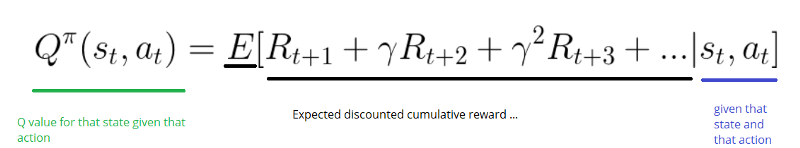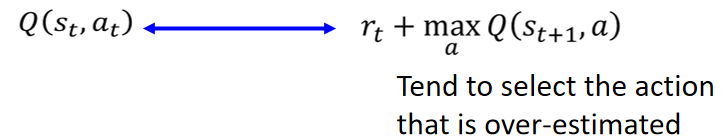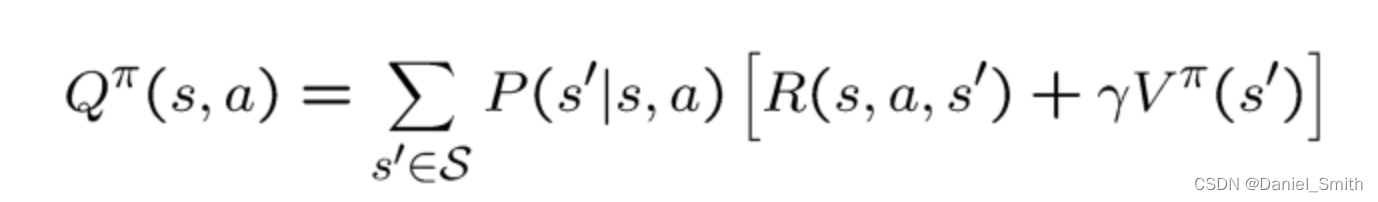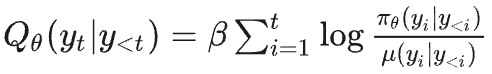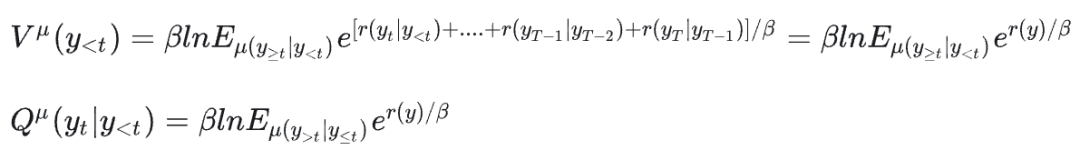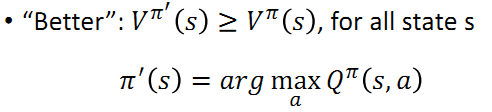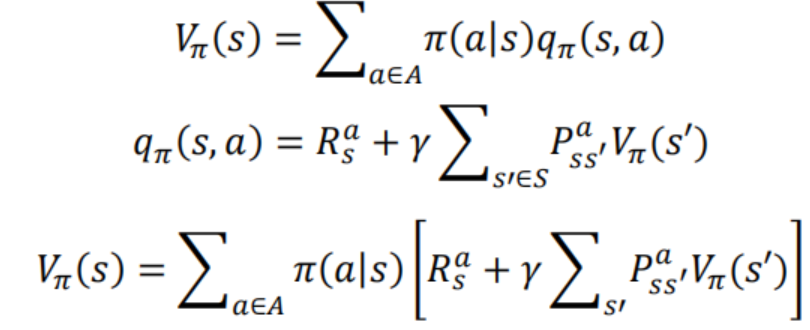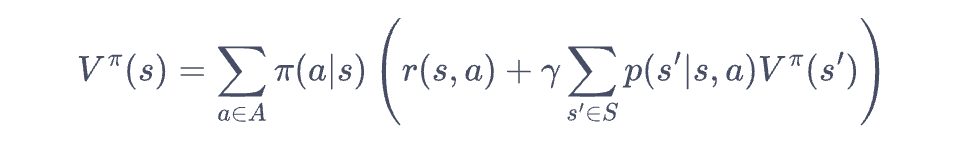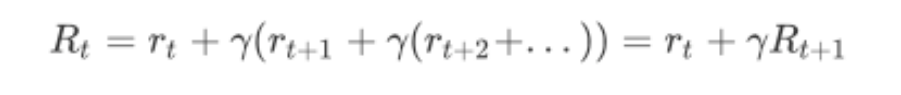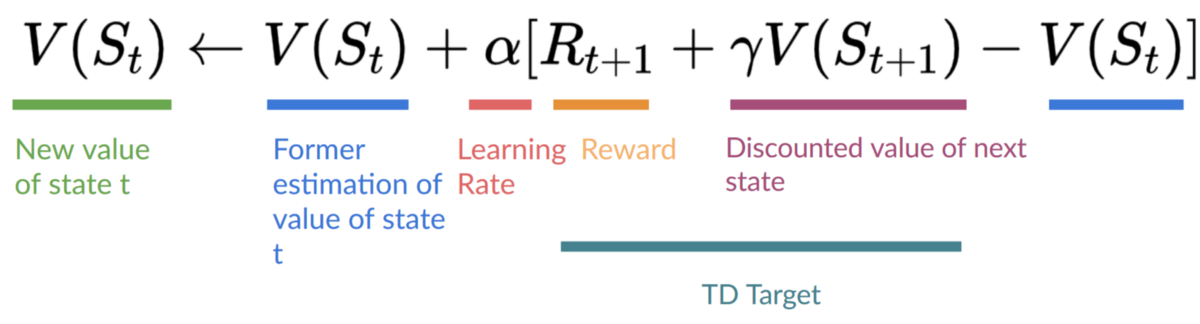Showing 117 of 117on this page. Filters & sort apply to loaded results; URL updates for sharing.117 of 117 on this page
What is the Q function and what is the V function_q function和v-CSDN博客
The Two Layer Neural Networks for Q function approximation. v = [v (s ...
Plots of the V (q) function for the linear Brownian motion and the ...
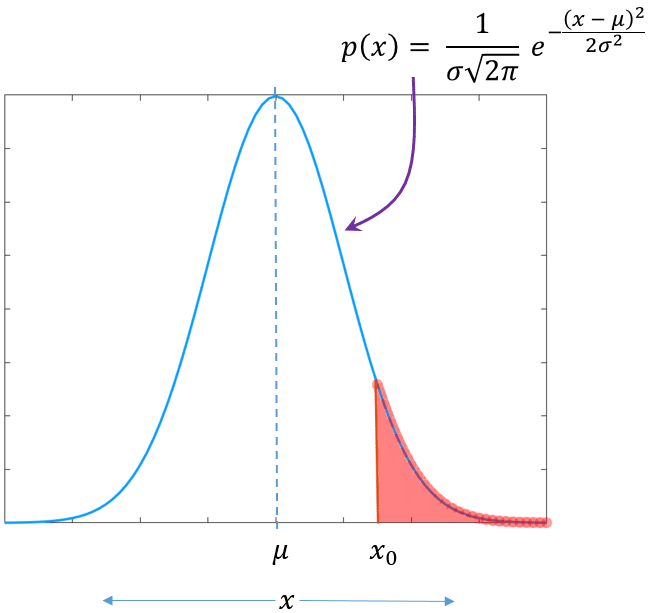
Q function and Error functions : demystified - GaussianWaves
Q Cycle Function at Oscar Goff blog
Q function curve when U0 = 400 V. | Download Scientific Diagram
Applied Reinforcement Learning V: Normalized Advantage Function (NAF ...
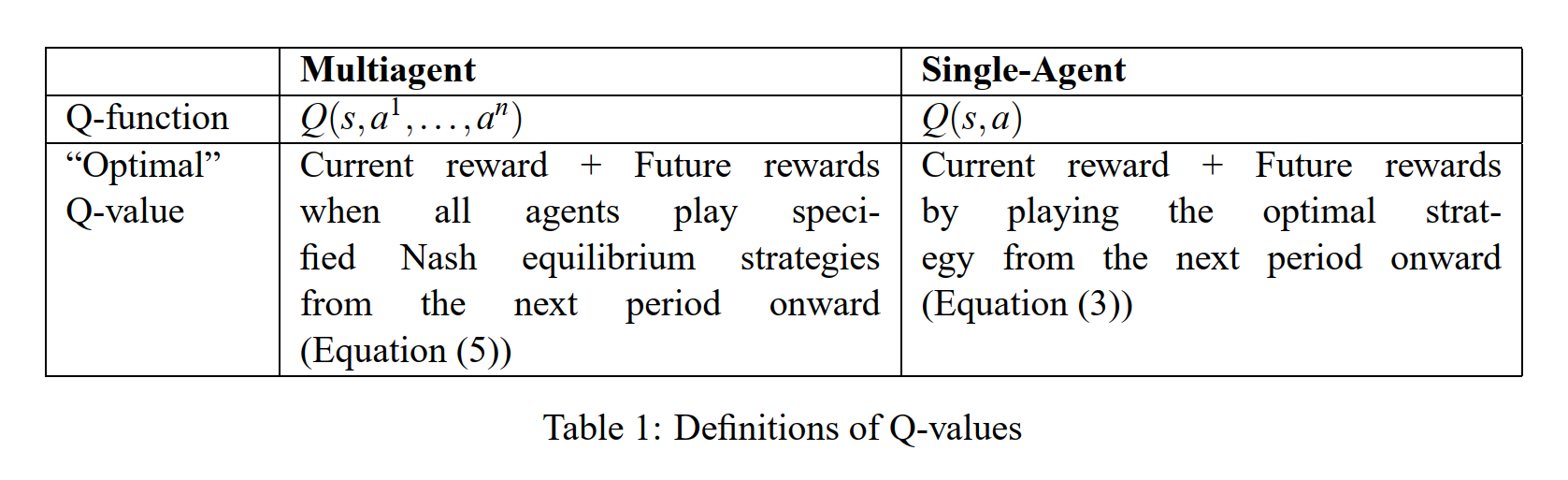
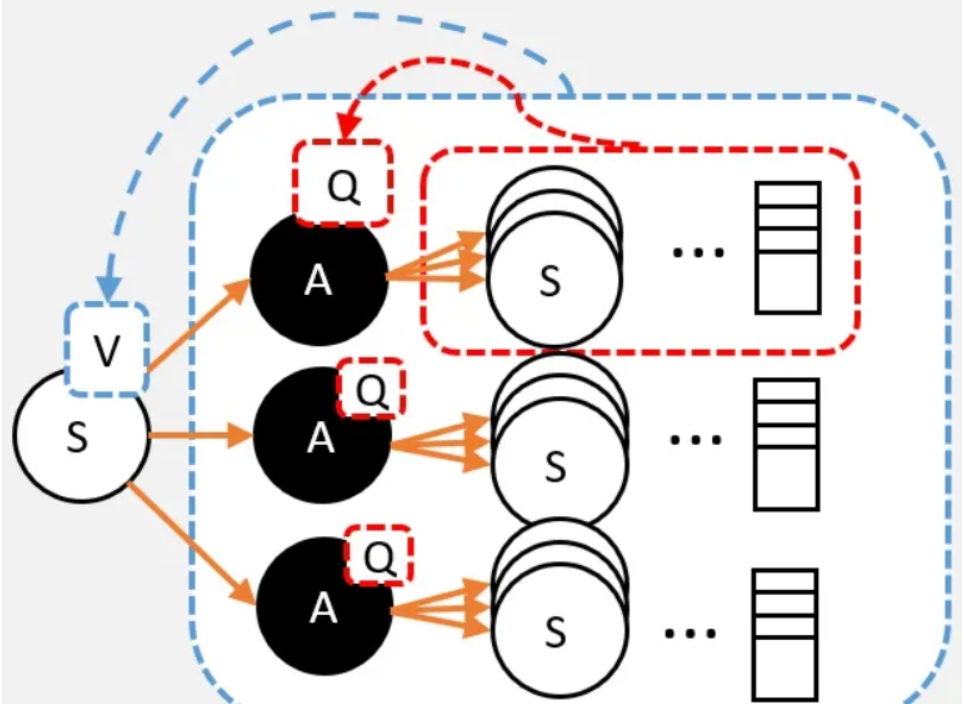
reinforcement learning - RL Advantage function why A = Q-V instead of A ...
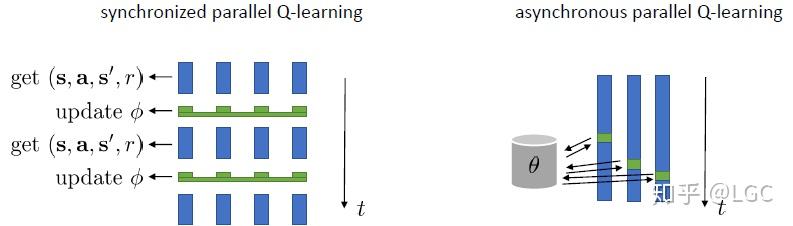
【CS285第8讲】Deep RL with Q Functions - 知乎
Q-learning和Deep Q Network (DQN) 深度解析_q-learning 与deep-q-learning的区别与联系 ...
Reinforcement learning with Deep Q Networks | Anyscale
reinforcement learning - Is my understanding of the value function, Q ...
CS285深度强化学习笔记3——马尔科夫决策过程 & 强化学习目标 & RL结构 & RL类型 - 知乎
34 - 第十二节 Deep Reinforcement learning 2020 Actor-Critic - 知乎
【学习笔记】强化学习_李宏毅 强化学习-CSDN博客
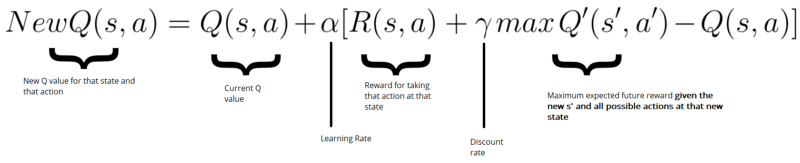
狗都能看懂的Q-Learning强化学习算法讲解_qlearning算法-CSDN博客
Q-function Q函数 (维基百科)-CSDN博客
Reinforcement Learning之Q-Learning - Python实现 - LOGAN_XIONG - 博客园
DQN 笔记 State-action Value Function(Q-function)_状态动作价值函数-CSDN博客
强化学习(Reinforcement Learning, RL)初探 - 郑瀚 - 博客园
强化学习RL 02: Value-based Reinforcement Learning_radomly sample n ...
【强化学习】Q-Learning算法详解_qlearning算法详解-CSDN博客
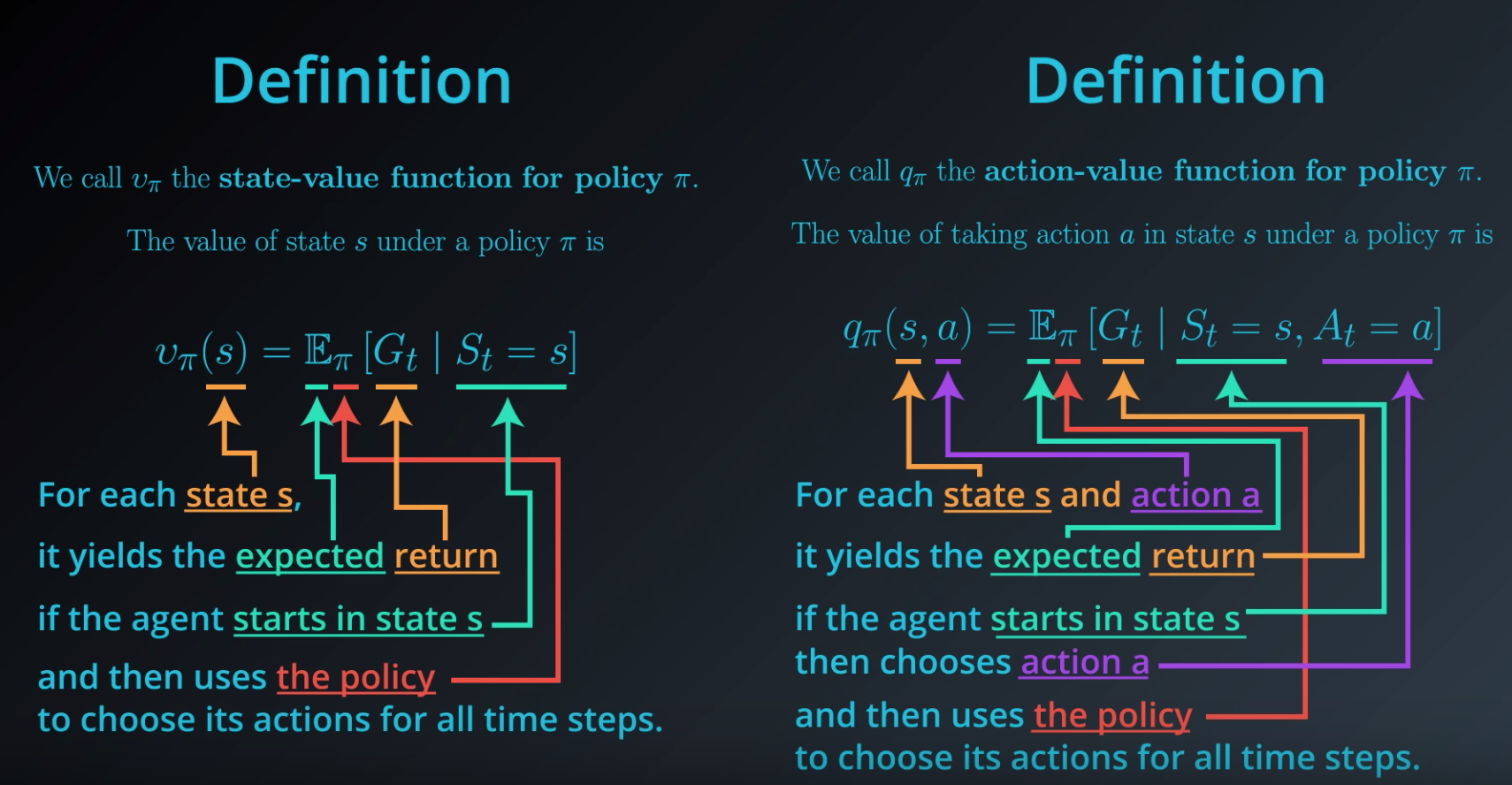
在强化学习rl中对于state value function和state action value function的理解_rl state ...
Lecture 13(Extra Material):Q-Learning-CSDN博客
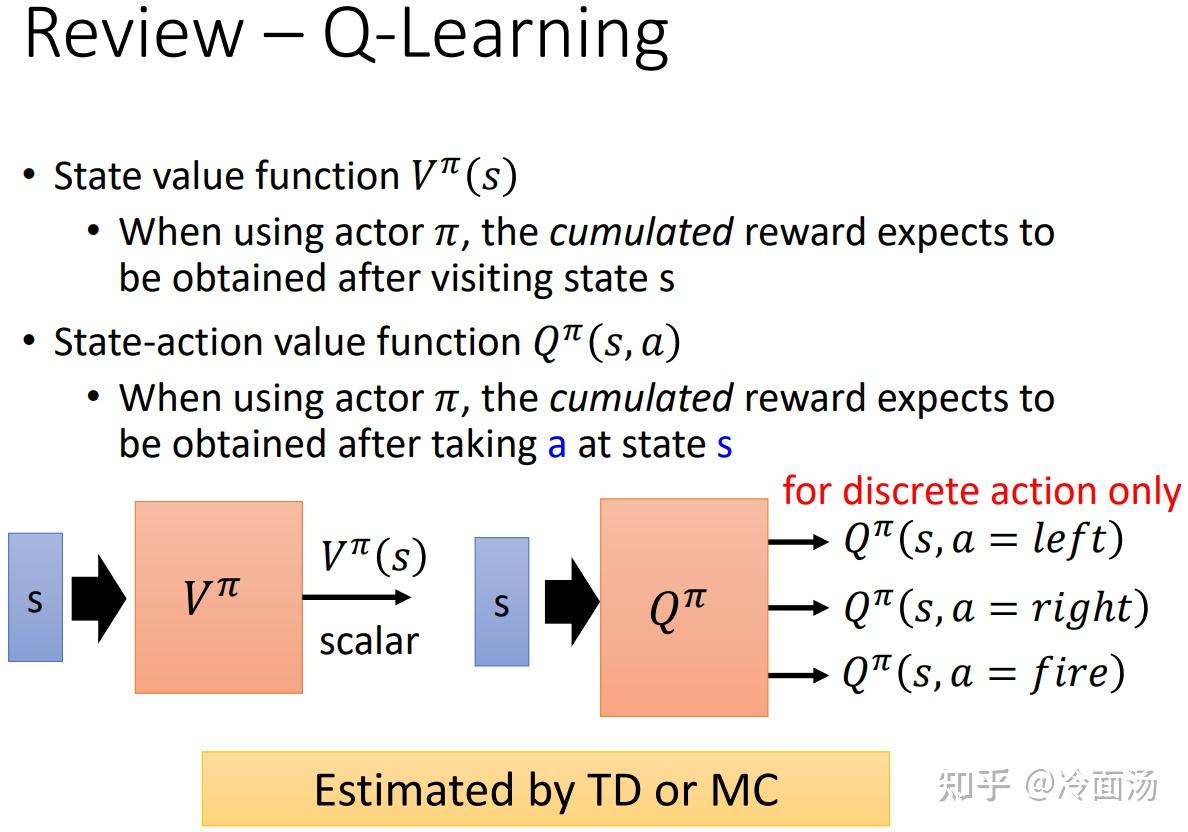
强化算法里,状态值函数V和状态-动作函数Q的区别? - 知乎
5.10记录 强化学习的Q值和V值_强化学习q函数和v函数-CSDN博客
【李宏毅深度强化学习笔记】3、Q-learning(Basic Idea)_深度强化学习 reward突然为0-CSDN博客
强化学习Q-learning入门_iq-learn-CSDN博客
论文笔记之:Dueling Network Architectures for Deep Reinforcement Learning ...
【深度强化学习】6. Q-Learning技巧及其改进方案_改进qlearning-CSDN博客
博弈论与强化学习 算法 一 MinimaxQ, NashQ ,FFQ - 英飞 - 博客园
强化学习之Q-learning algorithm学习总结-CSDN博客
Reinforcement Learning with Q-Learning - Part 1_Mangs-Python
强化学习之Q-learning_老鼠吃奶酪 强化学习-CSDN博客
【李宏毅深度强化学习笔记】4、Q-learning更高阶的算法_dueling q-learning-CSDN博客
机器学习——强化学习Q_learning算法_q learning图-CSDN博客
深度强化学习03价值学习-CSDN博客
强化学习中的Q值和V值_强化学习 q值-CSDN博客
强化学习(Reinforcement Learning)知识整理_优势函数-CSDN博客
机器学习——强化学习状态值函数V和动作值函数Q的个人思考_强化学习中状态值函数的定义-CSDN博客
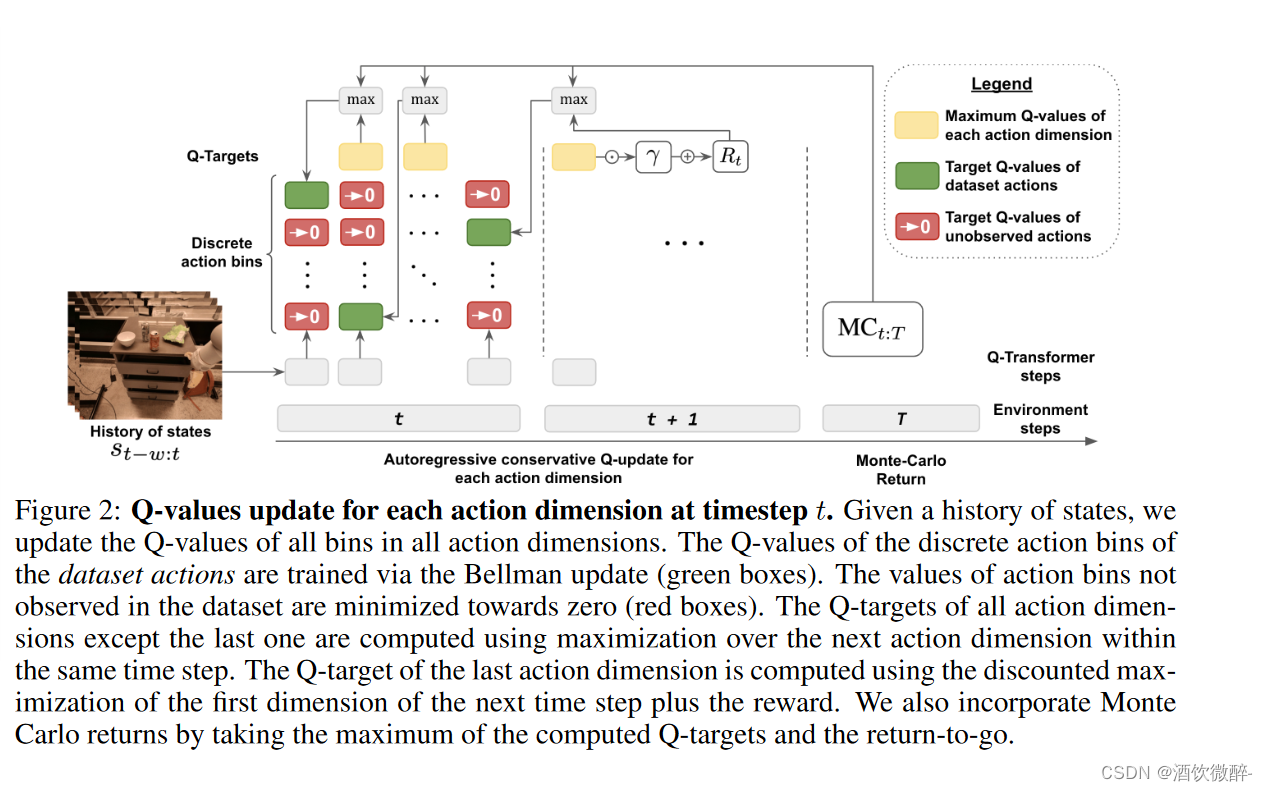
论文阅读--Q-Transformer: Scalable Offline Reinforcement Learning via ...
Data Augmentation in Reinforcement Learning - 知乎
Qlearning的PPT资源-CSDN下载
【强化学习论文解读 2】 Theory and application to reward shaping_policy invariance ...
Conservative Q-Learning for Offline Reinforcement Learning - 穷酸秀才大草包 - 博客园
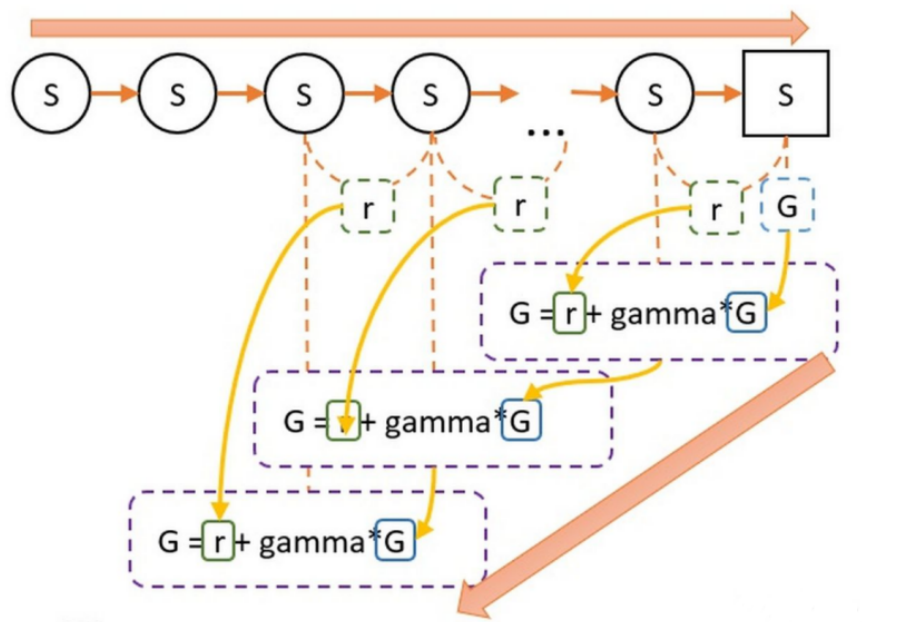
强化学习——贝尔曼最优方程_贝尔曼方程ddp-CSDN博客
强化学习Q-learning算法从原理到Python代码实现-开发者社区-阿里云
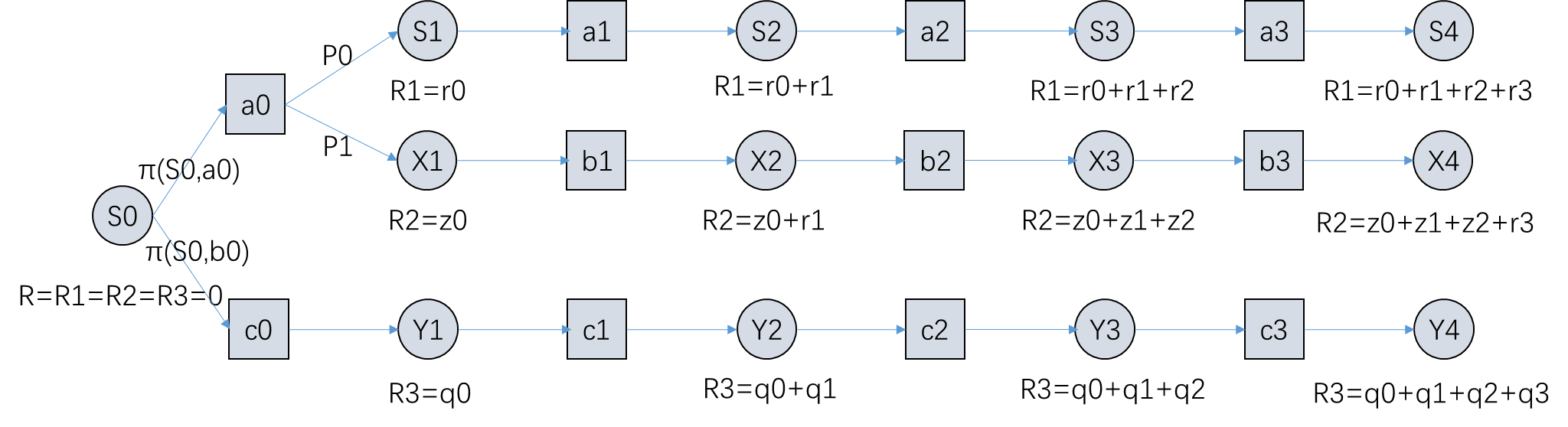
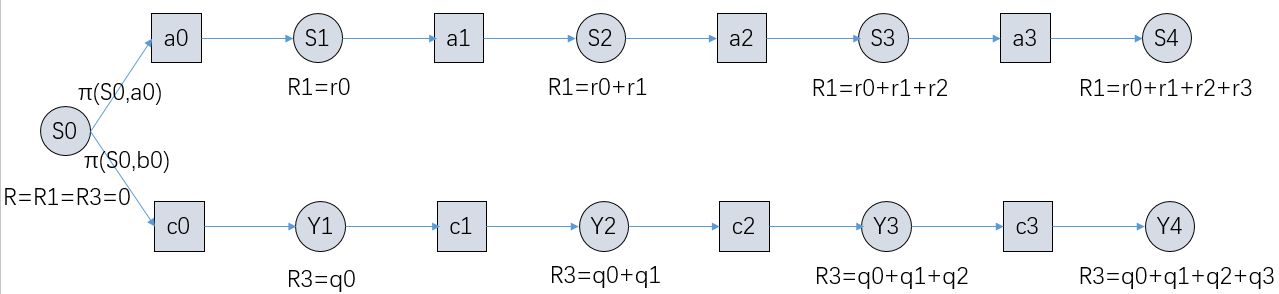
DPO作者新作|From r to Q* - 智源社区
为什么DQN不需要important sampling?——强化学习_dqn为什么不用重要性采样-CSDN博客
Enhancing Multi-Step Reasoning Abilities of Language Models through ...
【强化学习与最优控制】笔记(九)值函数,Q函数和策略空间的近似 - 知乎
DQN(Deep Q-learning)入门教程(二)之最优选择 - 渣渣辉啊 - 博客园
【自用笔记】Q—learning-CSDN博客
强化学习Q、V的区别_强化学习v和q的区别-CSDN博客
Branching Reinforcement Learning_rm算法-CSDN博客
From $r$ to $Q^*$: Your Language Model is Secretly a Q-Function - 智源社区论文
深度学习--强化学习--基本概念Q V--94 - jack-chen666 - 博客园
模型预测控制与强化学习-论文阅读(一)Integration of reinforcement learning and model ...
Dueling Network Architectures for Deep Reinforcement Learning(Dueling ...
RL-01:Q-Learning算法理解及实例应用_qlearning算法应用-CSDN博客
【笔记2-3】李宏毅深度强化学习笔记(三)Q-Learning_李宏毅深度学习自学笔记整理-CSDN博客
Reinforcement Learning - fxjwind - 博客园
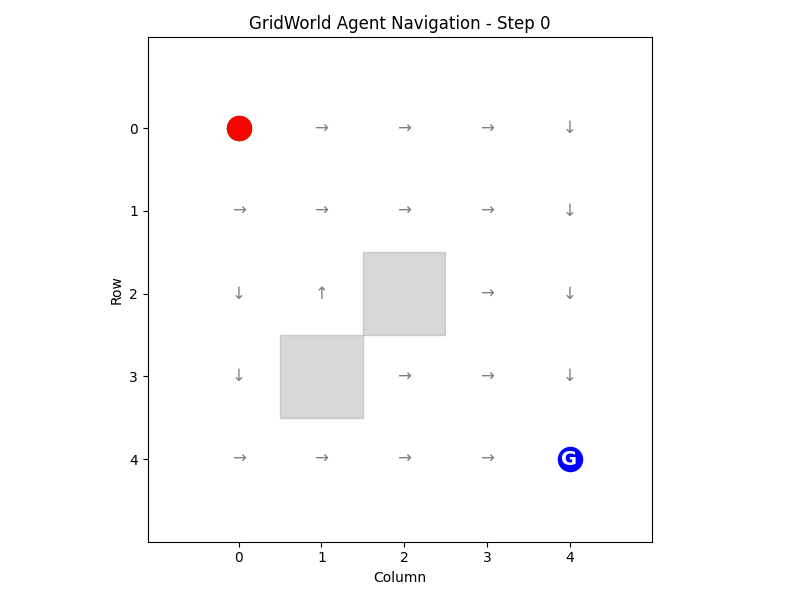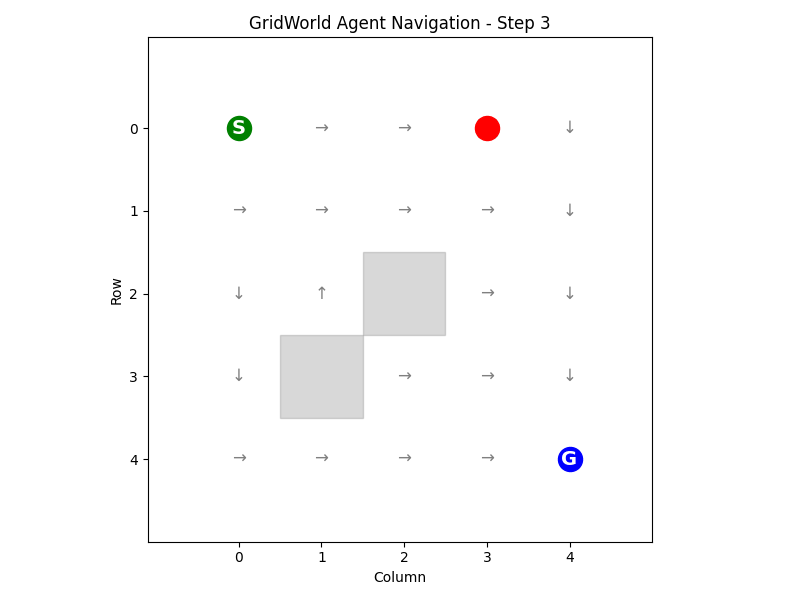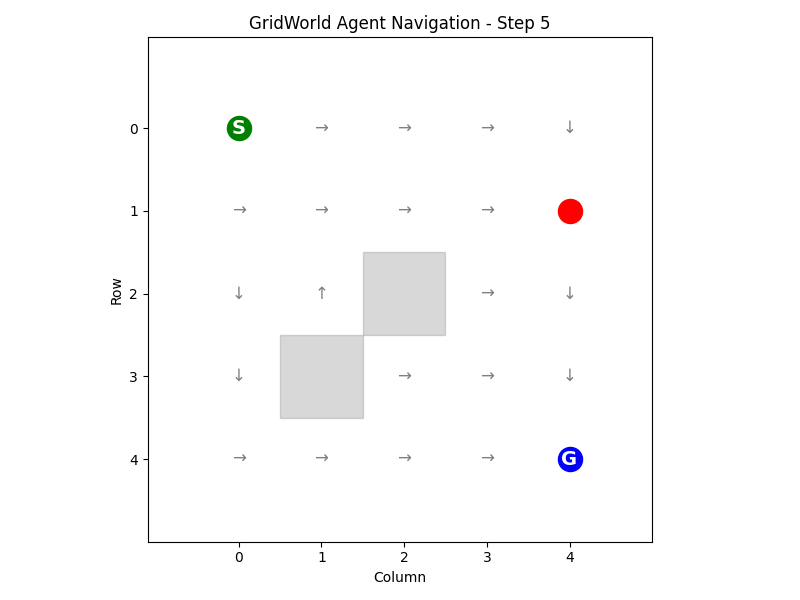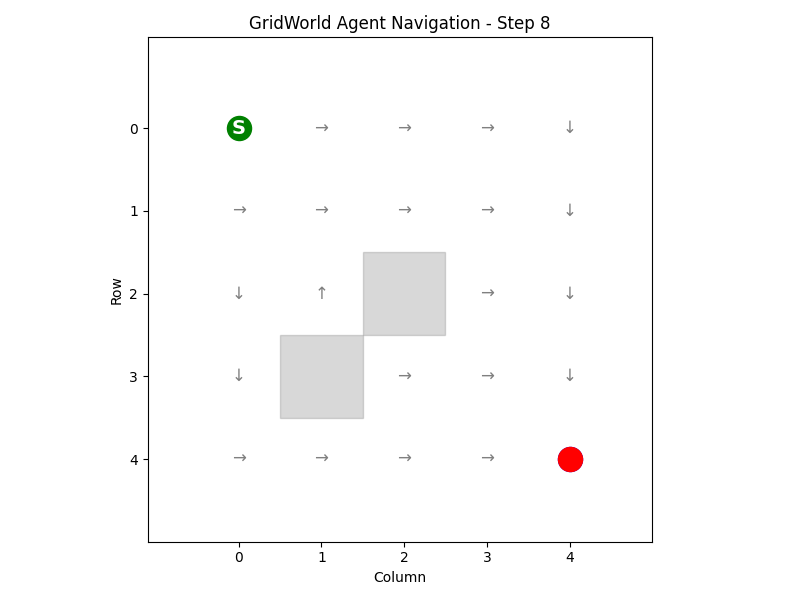
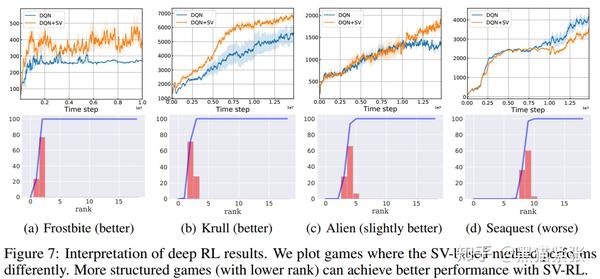
PN-40: Structured Value-based RL (ICLR 2020) - 知乎
基于强化学习与深度强化学习的游戏AI训练_基于强化学习的游戏控制策略训练-CSDN博客
全球名校AI课程库(17)| Stanford斯坦福 · 强化学习课程『Reinforcement Learning』 - 知乎
强化学习分类与汇总介绍-CSDN博客
干货 | 基于深度强化学习的轨迹规划(附代码解读)-CSDN博客
讲解基于模型的强化学习原理Dyna与随机打靶算法-开发者社区-阿里云
论文理解【Offline RL】——【DT】Decision Transformer: Reinforcement Learning via ...
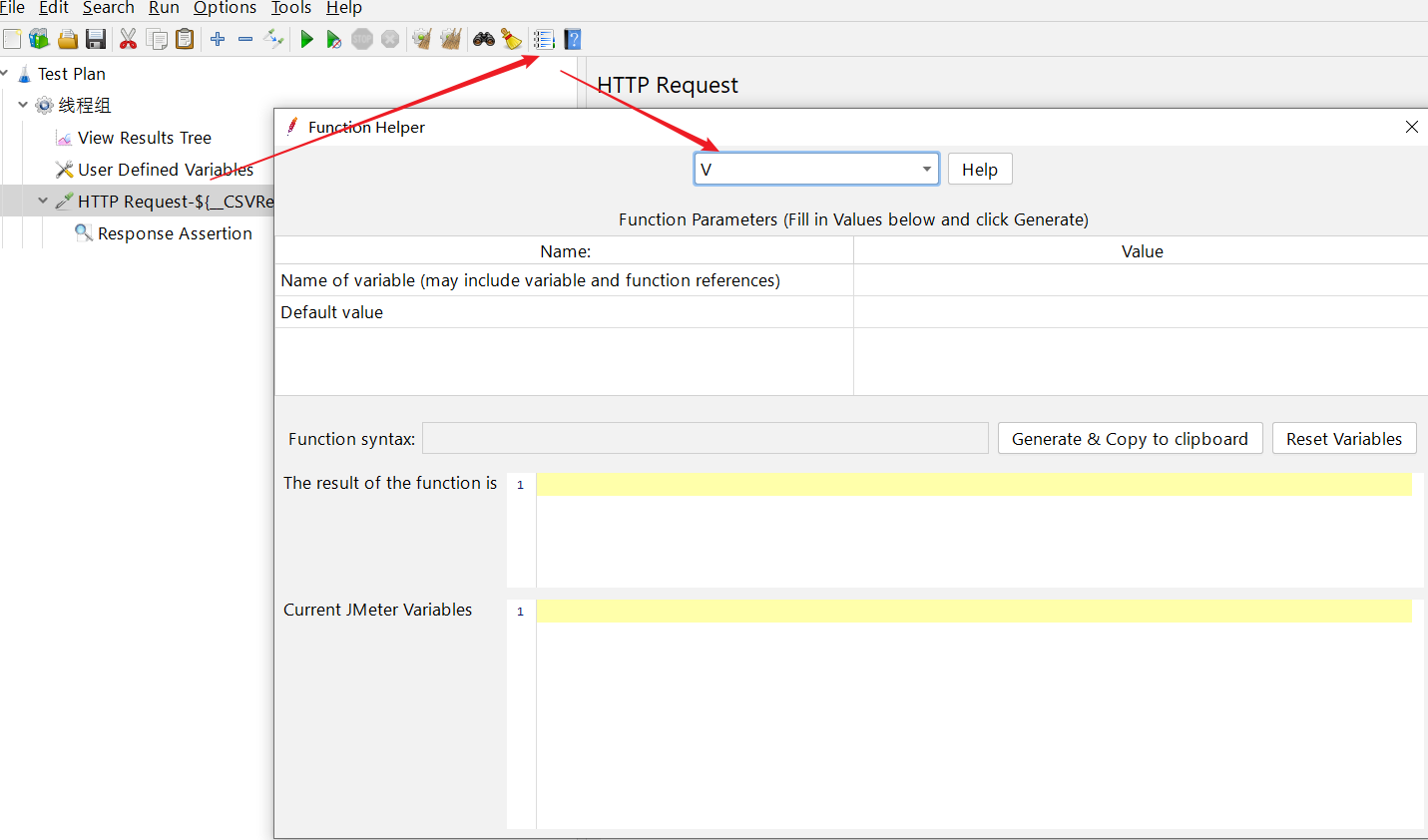
JMeter函数助手之V函数 - xyztank - 博客园
迁移学习强化学习多任务学习概念原理方法-开发者社区-阿里云
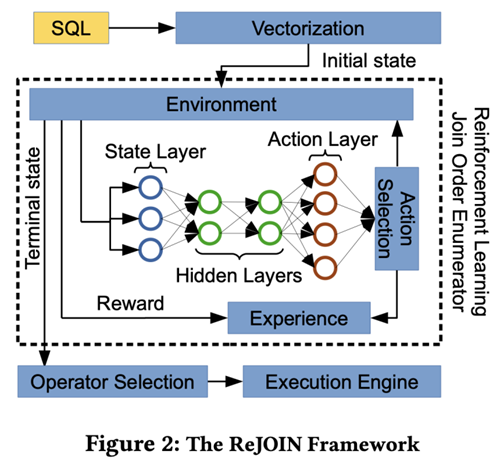
一种将 Tree-LSTM 的强化学习用于连接顺序选择的方法【SQL查询】 - 墨天轮
全球名校AI课程库(17)| Stanford斯坦福 · 强化学习课程『Reinforcement Learning』-阿里云开发者社区
强化学习——SAC算法_sac强化学习-CSDN博客
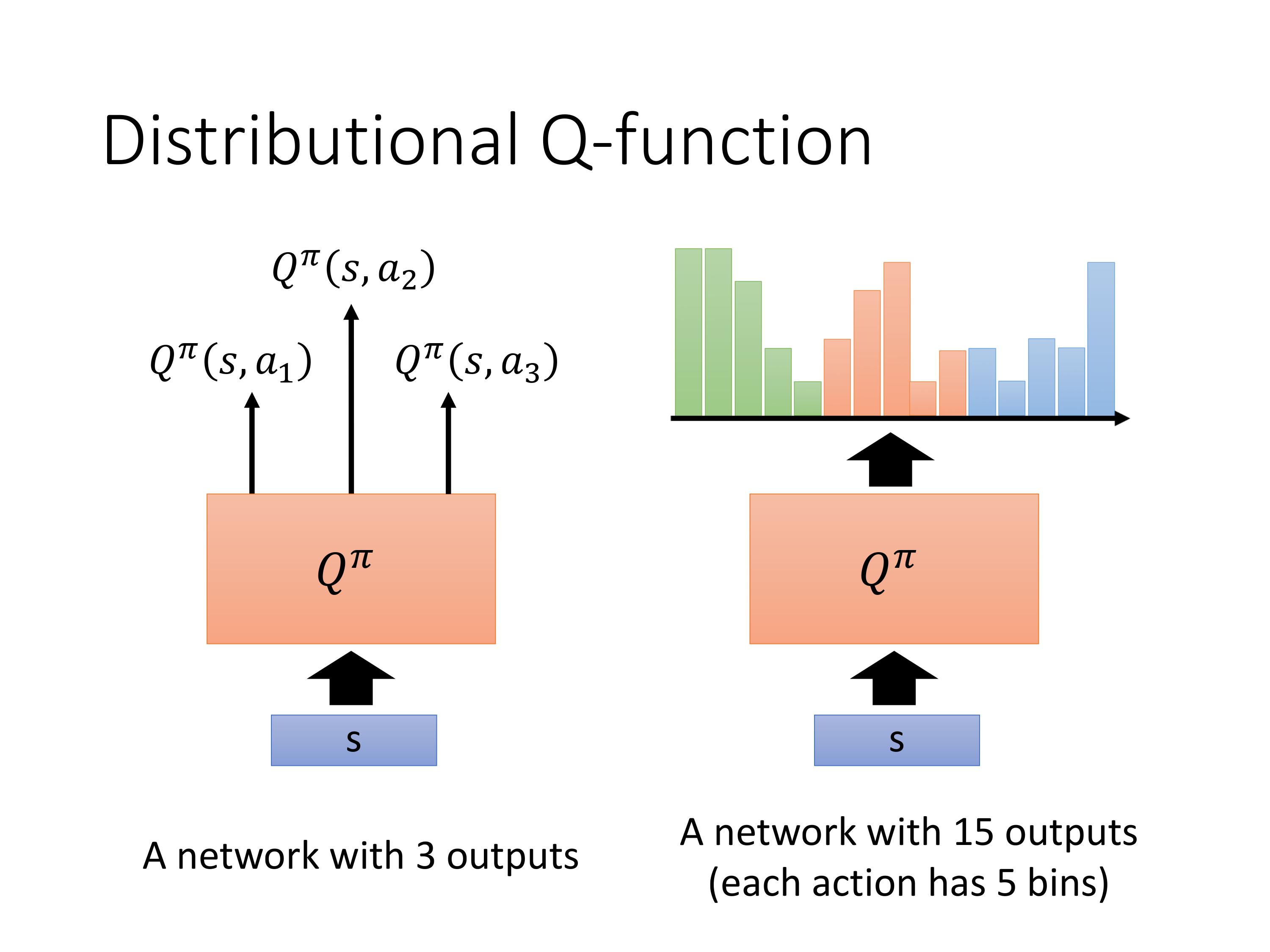
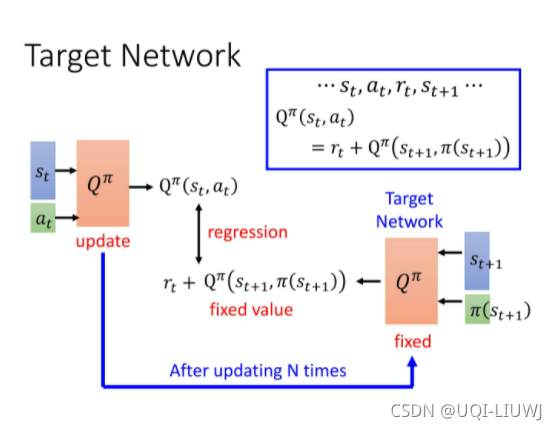
EasyRL 强化学习笔记 7、8章节(DQN进阶,DQN连续动作)_dqn输出多个动作-CSDN博客
【万字长文】强化学习笔记(Reinforcement Learning,RL)非常详细,初级入门-CSDN博客
强化学习(4):Double DQN、Prioritized Experience Replay DQN和Dueling DQN_优先级采样 ...
(转) Deep Learning in a Nutshell: Reinforcement Learning-阿里云开发者社区
一文看懂什么是强化学习?应用场景和主流算法_勇闯天涯的虾客_新浪博客
LM-9017-优邦亮太阳能照明
An Introduction to Q-Learning Part 2/2
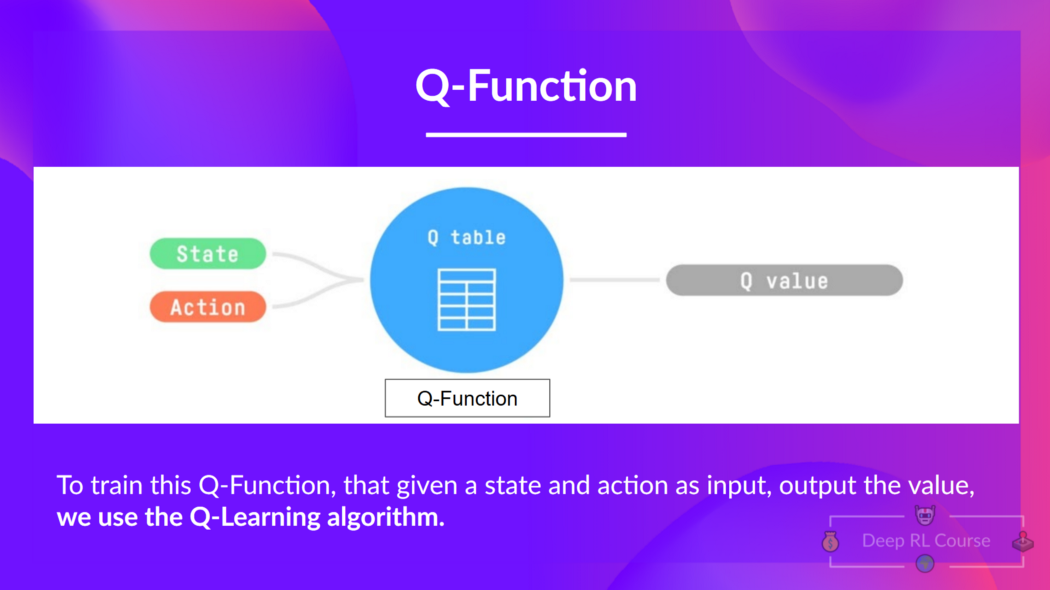
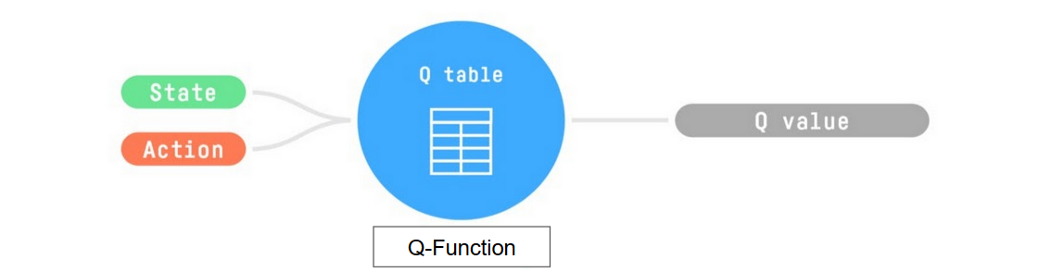
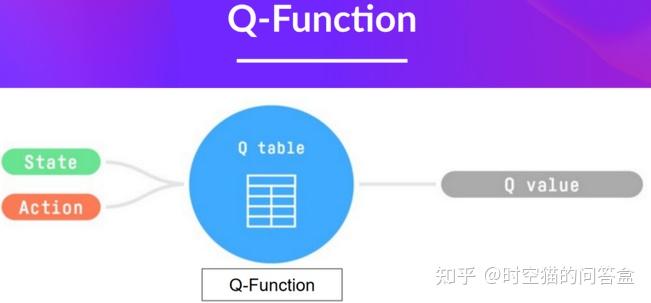
Q-Function
Structure of Q-Function. Convs represents three convolutional layers ...
An Introduction to Q-Learning: A Tutorial For Beginners | DataCamp
Q-Function: Definition, Approximation, and Properties | Slides Statics ...
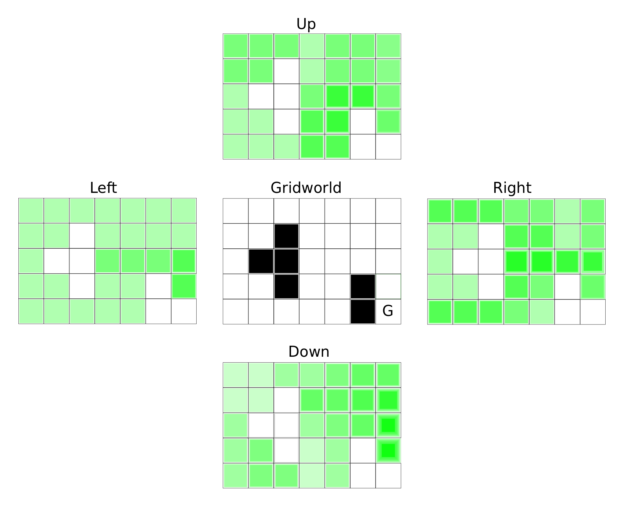
Introducing Q-Learning - Hugging Face Deep RL Course
DRL tutorial | Zahra Niazi
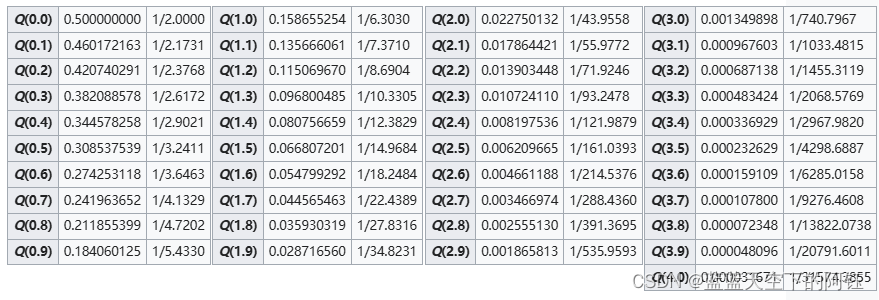
Table of Q-function values | Study notes Physics | Docsity
强化学习基础(二):Q-Learning - 知乎
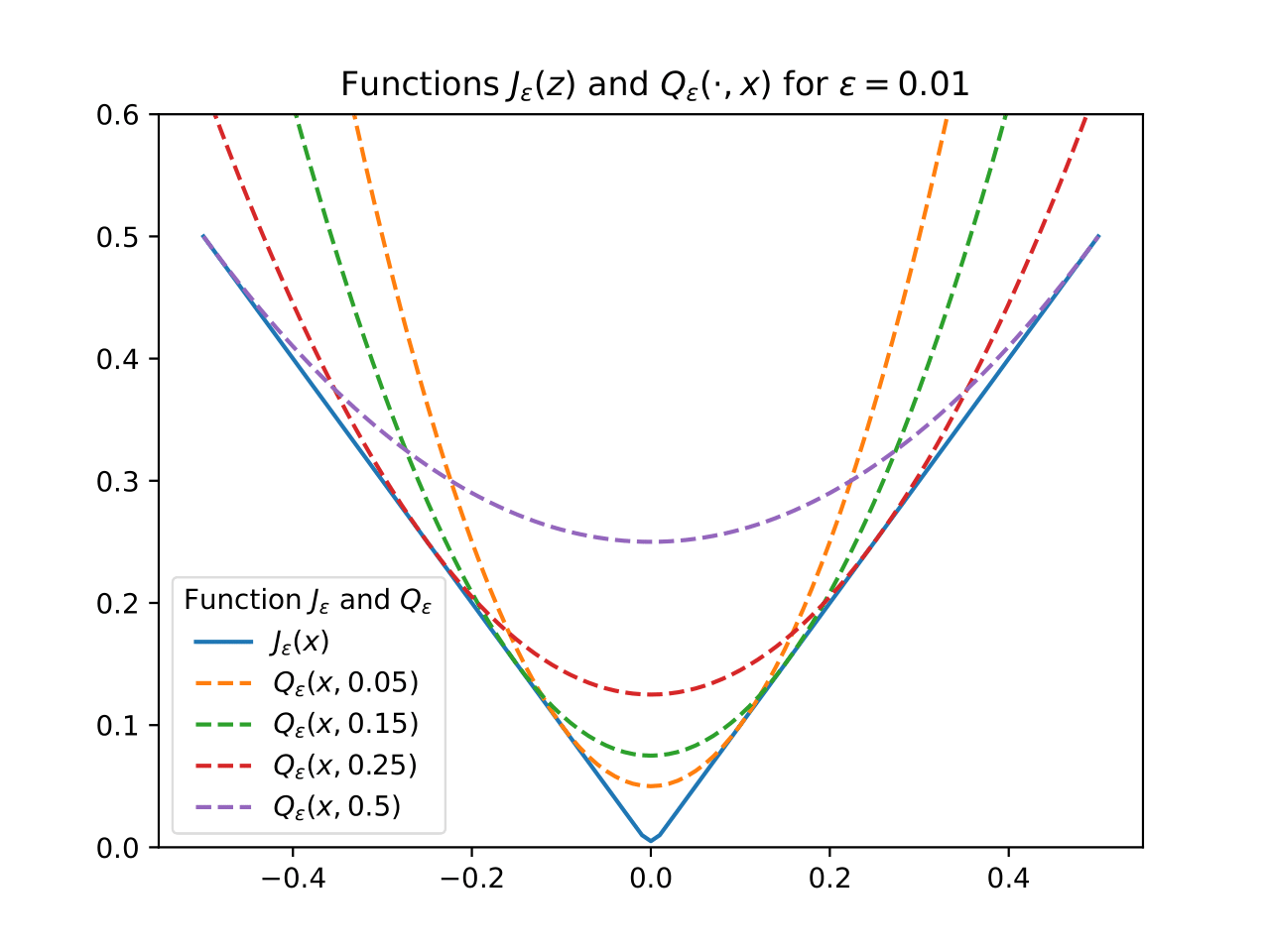
Claudio Mayrink Verdun
Effective Reinforcement Learning for Mobile Robots William D
Q-function for different mismatch levels. | Download Scientific Diagram
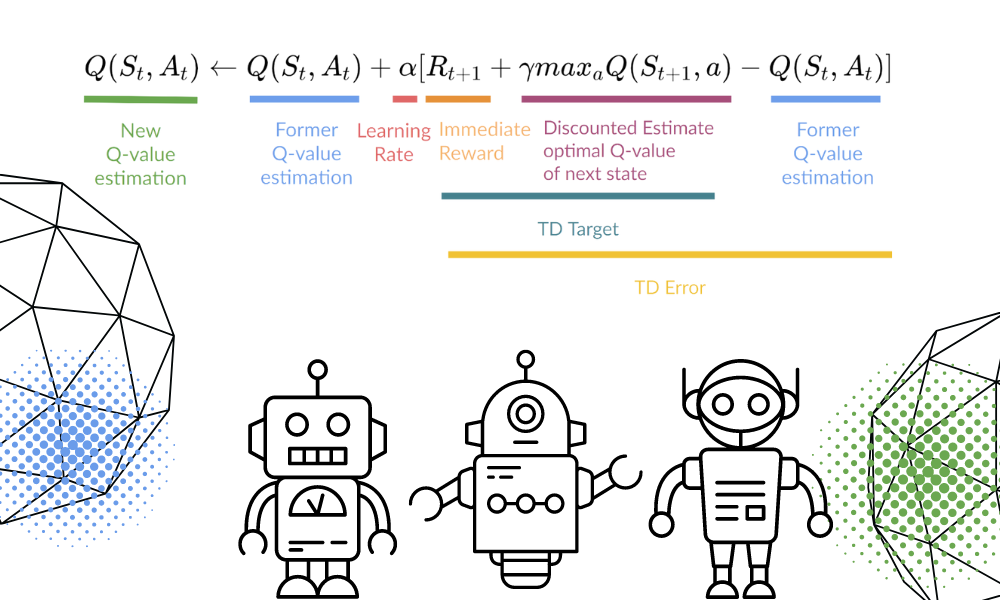
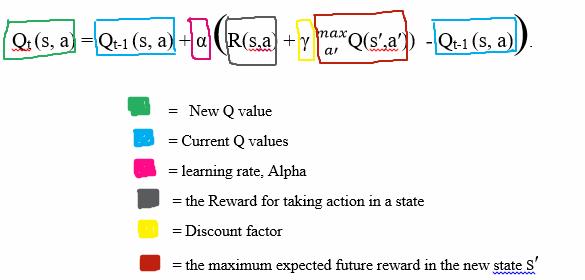
The Deep Q-Learning Algorithm - Hugging Face Deep RL Course
Q-learning Function: An Introduction
Reinforcement Learning, Part 1: Introduction and Main Concepts ...
[文献] Algorithms for Inverse Reinforcement Learning - 知乎